Artificial intelligence computer-aided diagnosis (AI-CAD) models can be fooled by an adversary to output the wrong diagnosis through the use of falsified images, according to a University of Pittsburgh study published in Nature Communications. The experiment “suggests an imperative need for continuing research on medical AI model’s safety issues and for developing potential defensive solutions against adversarial attacks.”“Under adversarial attacks, if a medical AI software makes a false diagnosis or prediction, it will lead to harmful consequences to patients, healthcare providers, and health insurances,” the researchers wrote.“In the efforts of building trustworthy deep learning-based AI software for clinical applications, it is thus vital to investigate behaviors and protection of AI software under adversarial input data,” they added.For their study, the researchers used mammogram images to develop a breast cancer detection model, training the deep learning algorithm to assess the differences between cancerous and benign cases with over 80% accuracy. Then they developed a “generative adversarial network,” or a computer program that produces false images by either inserting or removing cancerous areas from the negative or positive images. Once accomplished, the model was tested to see how the model would classify the adversarial images.The experiment found that “highly plausible adversarial samples” could be created on mammogram images with the advanced GAN algorithms to trick the AI model to output the wrong breast cancer diagnosis.The manipulated samples fooled the AI-CAD model 69.1% of the time for images that would have typically been correctly classified by the model. In contrast, five breast imaging radiologists visually identify 29% to 71% of the adversarial samples. The researchers deduced that certified radiologists may be able to spot the fake images using their experience and medical knowledge, particularly if the falsified images are less plausible, such as obvious notices, incompliant anatomical structures, and the like.Although radiologists could likely spot a fake image and not make or trust a diagnosis, the trouble lies with the AI model and its failure to spot the difference. The researchers noted that when “an automated detection of adversarial inputs is not in place, human experts’ visual observations may provide a realistic added protection by identifying potential adversarial inputs.”“Certain fake images that fool AI may be easily spotted by radiologists. However, many of the adversarial images in this study not only fooled the model, but they also fooled experienced human readers,” said Shandong Wu, director of the Intelligent Computing for Clinical Imaging Lab and the Pittsburgh Center for AI Innovation in Medical Imaging and study’s lead researcher. “Such attacks could potentially be very harmful to patients if they lead to an incorrect cancer diagnosis,” he added.Further, while certified human radiologists could mostly identify the adversarial samples, the researchers stressed that it’s not a reliable method for safely detecting all potential adversarial samples. Educating radiologists could improve their performance, but more research is needed on the safety issues posed by medical AI models and to develop potential defense tools.The next step of their research intends to address these risks by training an AI model to detect adversarial attacks, including pre-generated adversarial images and teaching the model to recognize manipulated images.As many larger and leading health systems continue to adopt AI into medical infrastructure, it’s imperative these leaders fully grasp the potential impacts of cybersecurity risks to hospital technology systems and to train personnel about these potential threats.
Threat Management, Penetration Testing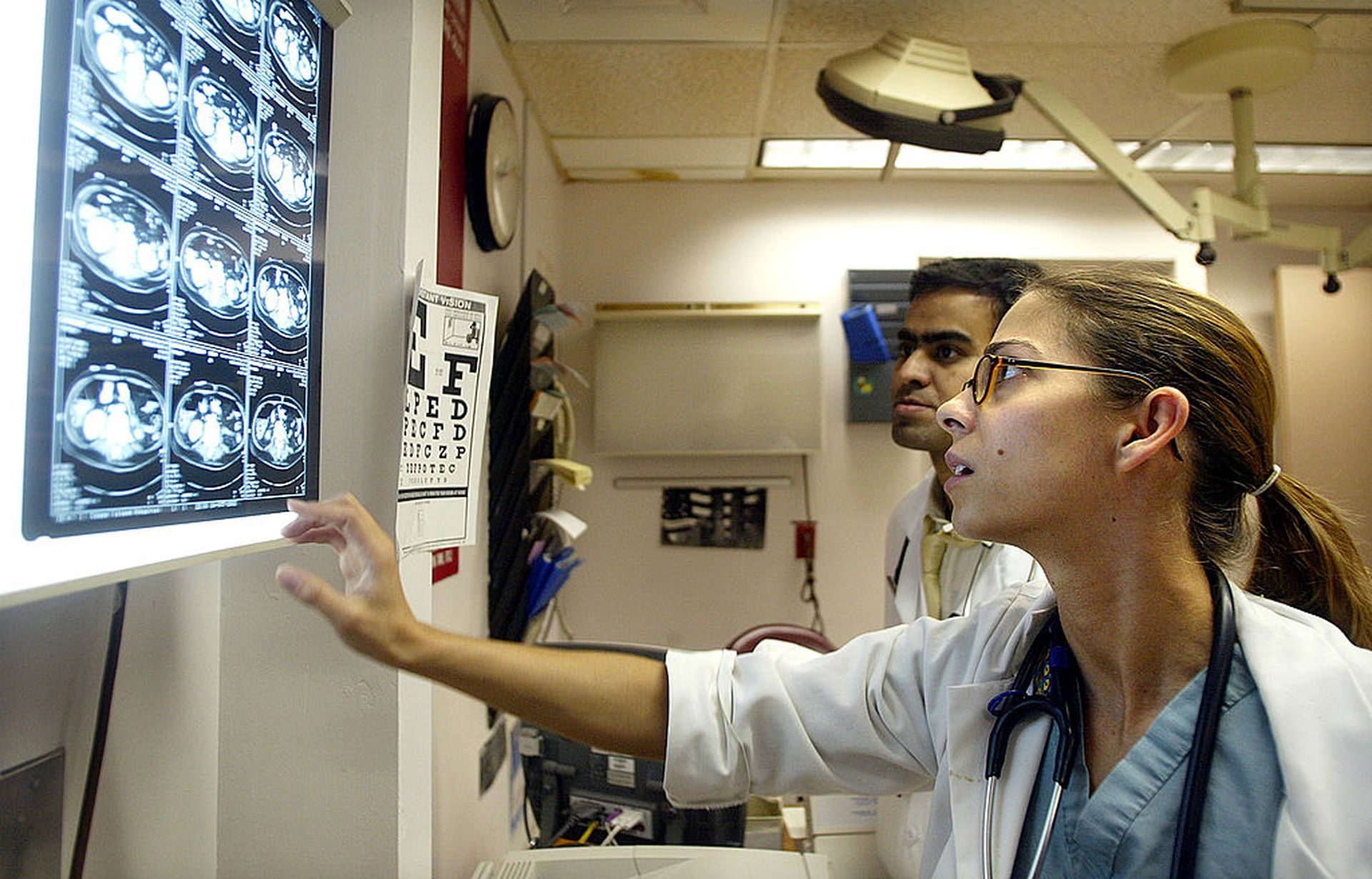

Study: Medical AI diagnosis models can be manipulated to output wrong diagnosis
University of Pittsburgh researchers say AI-CAD models can be faked to produce a wrong diagnosis. Pictured: Dr. Karen Barbosa views CT scans in the emergency room at Coney Island Hospital Oct. 5, 2002, in the Brooklyn borough of New York City. (Photo by Mario Tama/Getty Images)
Jessica Davis
The voice of healthcare cybersecurity and policy for SC Media, CyberRisk Alliance, driving industry-specific coverage of what matters most to healthcare and continuing to build relationships with industry stakeholders.



Related Events
Get daily email updates
SC Media's daily must-read of the most current and pressing daily news
You can skip this ad in 5 seconds